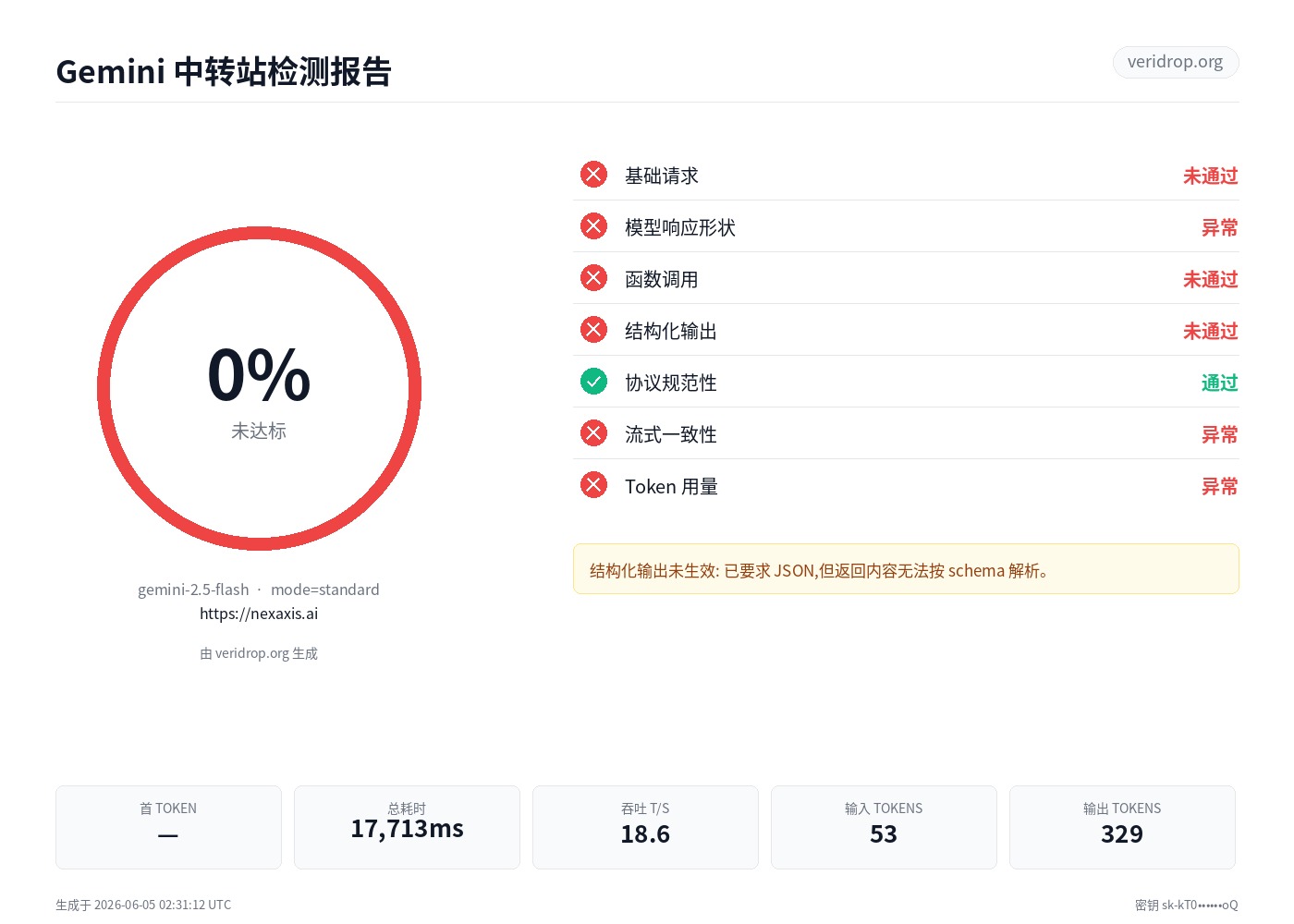
nexaxis.ai Gemini 中转站检测报告
检测无效 ·
模型 gemini-2.5-flash · 模式 standard ·
中转站 https://nexaxis.ai
{kind=link}
检测时中转站上游正在限流 / 过载(HTTP 429「请稍后再试」),大部分检测请求被挡下,这次没拿到有效结果。这是临时容量问题,不代表中转站质量——过几分钟重试一次通常就正常。
这类余额不足、访问限制或临时上游错误不是中转站质量分,Veridrop 会从域名聚合评分中排除。
—
检测无效
由 https://veridrop.org 生成
- 基础请求 未通过
- 模型响应形状 异常
- 函数调用 未通过
- 结构化输出 未通过
- 协议规范性 通过
- 流式一致性 异常
- Token 用量 异常
划重点:这份报告在说什么
这次没测成 —— 中转站当时太忙(限流)
你测的时候,这家中转站的上游正好在排队/过载,大部分请求被挡了回来(HTTP 429「请稍后再试」),所以这次没拿到结果。这不代表它质量差,就是当时人多。过几分钟再测一次,通常就正常了。
首 TOKEN
—
总耗时
17,713ms
吞吐 (T/S)
18.6
输入 TOKENS
53
输出 TOKENS
329
Gemini 检测项各自检查什么?
- 基础请求
- 发送最小
generateContent请求,确认接口可用且能提取 Gemini 文本响应。 - 模型响应形状
- 检查
modelVersion、responseId、finishReason、candidate 和 safety 字段是否完整。 - 函数调用
- 强制 Gemini 返回
functionCall,检查函数名和 args 是否是结构化对象。 - 结构化输出
- 使用
responseMimeType=application/json和responseSchema,检查返回内容能否按 schema 解析。 - 协议规范性
- 被动检查
candidates、content.parts、safetyRatings、usageMetadata等 Gemini 原生字段。 - 流式一致性
- 比较同一 prompt 的
generateContent与streamGenerateContent文本、结束原因和用量字段是否一致。 - Token 用量
- 检查
usageMetadata是否存在、Token 统计是否自洽,以及长短文本带来的 Token 增量是否合理。
这份报告帮你避坑了吗?
GitHub 加星支持 →
如果 Veridrop 的字段级证据对你有用,欢迎顺手给 GitHub 点个 Star,支持公开、可复核的中转站测评继续维护。