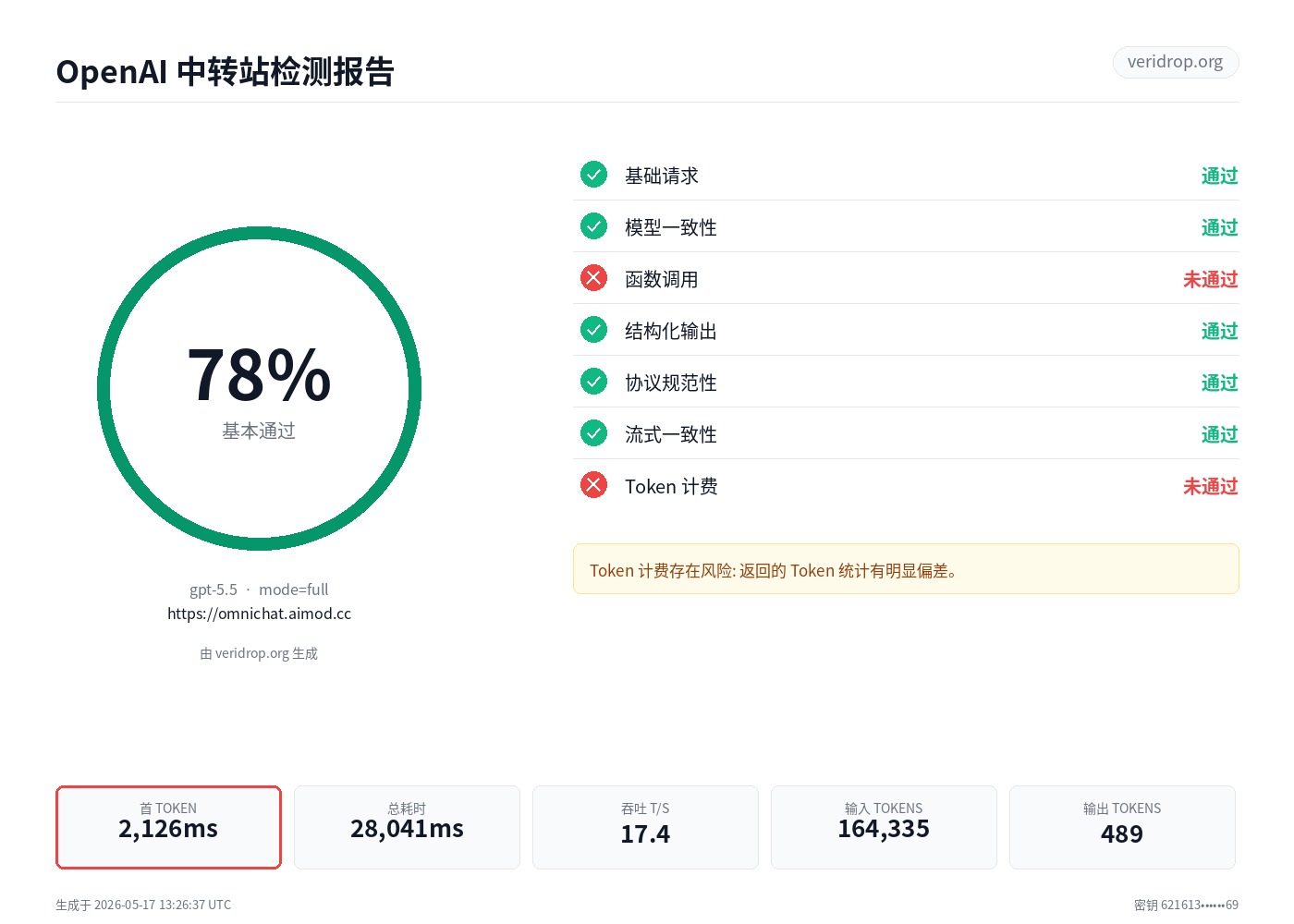
检测结果
模型:gpt-5.5 · 模式 full ·
中转站 https://omnichat.aimod.cc
{kind=link}
78%
基本通过
由 https://veridrop.org 生成
- 基础请求 通过
- 模型一致性 通过
- 函数调用 未通过
- 结构化输出 通过
- 协议规范性 通过
- 流式一致性 通过
- Token 计费 未通过
- 长上下文真实性 未通过
这份结果怎么理解?
Token 计费存在风险
Token 数明显异常: usage 字段、token 增量或流式/非流式统计存在明显问题,有虚报或统计错误风险。
首 TOKEN
2,126ms
总耗时
28,041ms
吞吐 (T/S)
17.4
输入 TOKENS
164,335
输出 TOKENS
489
OpenAI 检测项各自检查什么?
- 基础请求 (Basic Request)
- 发送最小 Chat Completions 请求,确认接口可用且能提取 assistant 文本。
- 模型一致性 (Model Consistency)
- 验证
response.model与请求模型匹配,并检查低温多次调用的输出 token 稳定性。 - 函数调用 (Function Calling)
- 强制 tool_choice,验证
call_ID、type=function、函数名和 arguments JSON。 - 结构化输出 (Structured Output)
- 使用
response_format=json_schema,检查返回内容能否按 schema 解析。 - 协议规范性 (Protocol)
- 被动检查
chatcmpl-ID、chat.completion、choices、finish_reason、usage 等官方字段。 - 流式一致性 (Integrity)
- 比较同一 prompt 的 stream 与 non-stream 文本、finish_reason 和 usage 是否一致。
- Token 计费
- 检查中转站返回的输入/输出 Token 数是否自洽,并和同一次检测里的流式/非流式结果、本地可预期的变化进行对比。
- 长上下文真实性 (Long Context)
- 需在提交时勾选启用 — 用 needle-in-haystack 在 32k → 100k → 200k tokens 三档探针,验证中转站是否真兑现宣传的 context window(识别截断 / 路由到小窗口模型)。极限档可按模型完整上限自适应探到 950k+。