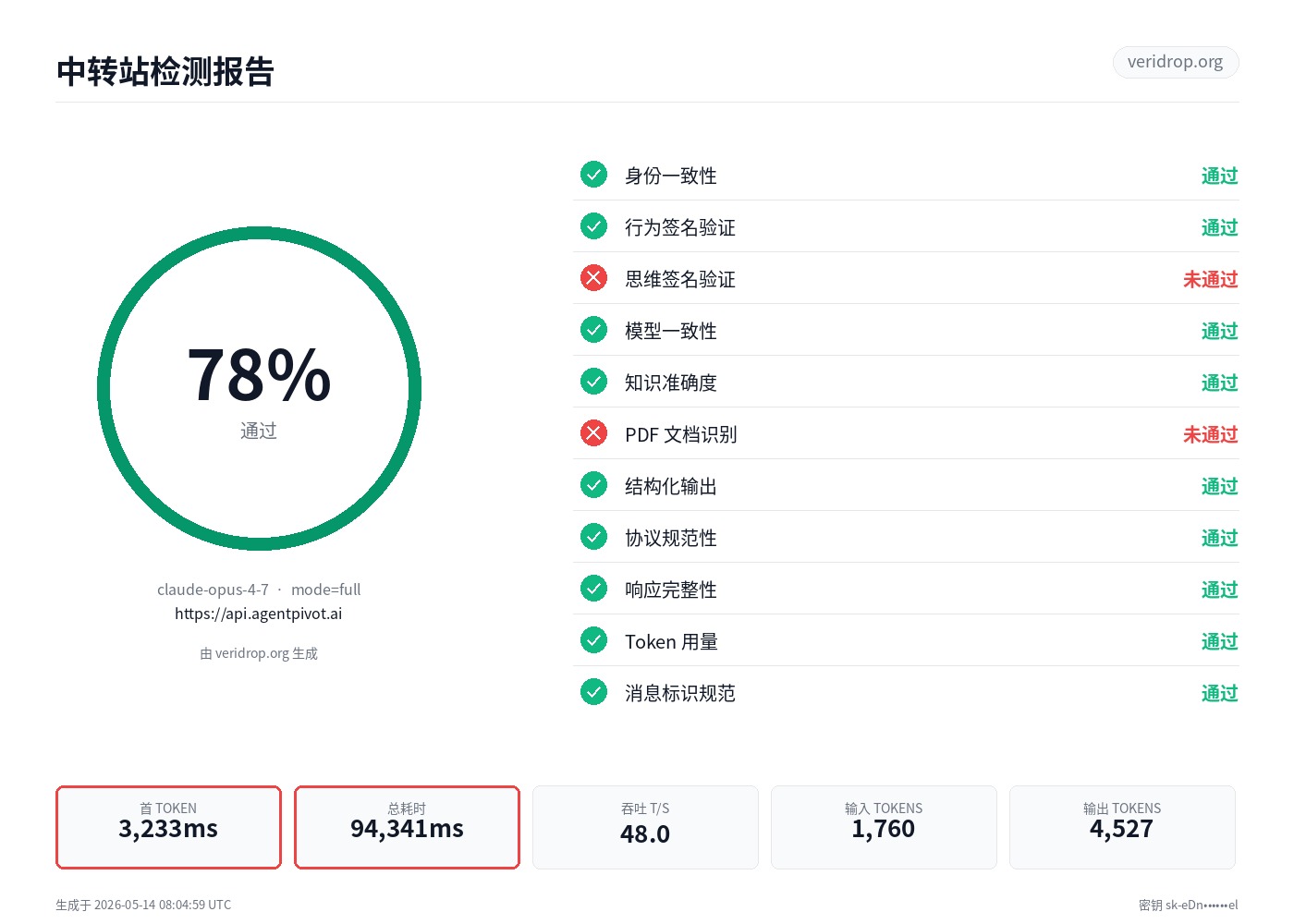
agentpivot.ai Claude 中转站检测报告
78/100 · 通过 ·
模型 claude-opus-4-7 · 模式 full ·
中转站 https://api.agentpivot.ai
· 品牌:agentpivot.ai · 实际 endpoint:api.agentpivot.ai
{kind=link}
78%
通过
由 https://veridrop.org 生成
- 身份一致性 通过
- 行为签名验证 通过
- 思维签名验证 未通过
- 模型一致性 通过
- 知识准确度 通过
- PDF 文档识别 未通过
- 结构化输出 通过
- 协议规范性 通过
- 响应完整性 通过
- Token 用量 通过
- 消息标识规范 通过
- 长上下文真实性 未启用
首 TOKEN
3,233ms
总耗时
94,341ms
吞吐 (T/S)
48.0
输入 TOKENS
1,760
输出 TOKENS
4,527
12 项检测各自检查什么?
- 身份一致性 (Identity)
- 询问模型自报身份,响应必须包含 "Claude" 与 "Anthropic",且不能自称是其他品牌(如 Kiro、AWS Q 等)。
- 行为签名验证 (Behavioral)
- 3 道行为指纹题(markdown 风格、列表偏好、拒绝语气),正版 Claude 有特征鲜明的回答模式。
- 思维签名验证 (Thinking) ⭐
- 核心检测:Claude thinking 块返回的加密
signature字节,任何中转站都无法伪造。 - 模型一致性 (Consistency)
- 验证
response.model与请求一致,且多次调用输出长度稳定(变异系数 CV)。 - 知识准确度 (Knowledge)
- 5 道关于 Anthropic 公司的常识题(CEO、HQ、Constitutional AI 等),错答多则说明背后不是真 Claude。
- PDF 文档识别
- 提交一份 base64 PDF + magic 字符串,检查模型能否正确提取——剥离 multimodal 的中转站会失败。
- 结构化输出 (Tool Use)
- 真实 tool_use 调用,验证
toolu_ID 前缀、JSON schema 匹配、stop_reason 等 5 项子项。 - 协议规范性 (Protocol)
- SSE 事件序列、content block 类型必须符合 Anthropic 官方规范(被动检测,不发额外请求)。
- 响应完整性 (Integrity)
- 同一 prompt 流式与非流式调用必须返回一致的文本、
input_tokens、stop_reason。 - Token 用量
- 检查 Claude Messages 的
usage.input_tokens/output_tokens是否存在、长短 prompt 增量是否合理、短输出是否没有超报,并用 stream 与count_tokens做交叉验证。 - 消息标识规范 (Message ID)
- 消息
id必须以msg_开头、tool 块以toolu_开头。UUID 或硬编码tool_1是典型造假特征。 - 长上下文真实性 (Long Context)
- 需在提交时勾选启用 — 用 needle-in-haystack 在 32k → 100k → 200k tokens 三档探针,验证中转站是否真兑现宣传的 context window(识别截断 / 路由到小窗口模型)。Anthropic 路径用官方
count_tokens端点精准预算 token,极限档可按模型完整上限自适应探到 950k+(Fable 5 / Opus 4.8 / Sonnet 4.6 / Opus 4.6/4.7 都是 1M)。
这份报告帮你避坑了吗?
GitHub 加星支持 →
如果 Veridrop 的字段级证据对你有用,欢迎顺手给 GitHub 点个 Star,支持公开、可复核的中转站测评继续维护。